
Mit Ollama ist es möglich, Large Language Models (LLMs) lokal auf deinem PC auszuführen. In diesem Beitrag zeige ich dir, wie du die Software installieren und nutzen kannst.
Was ist ein Large Language Model?
Ein Large Language Model (LLM) ist ein Sprachmodell, das für seine Fähigkeit bekannt ist, allgemeine Sprachgenerierung und andere Aufgaben der natürlichen Sprachverarbeitung wie Klassifikation zu erreichen. LLMs können für die Textgenerierung verwendet werden, eine Form der generativen KI, indem sie einen Eingabetext nehmen und wiederholt das nächste Token oder Wort vorhersagen. Das berühmte ChatGPT von OpenAI basiert auf einem Large Language Model, das es Nutzern ermöglicht, Gespräche zu verfeinern und zu steuern.
Installation von Ollama und Herunterladen von LLMs
Lass uns zunächst Ollama von der offiziellen Website ollama.com herunterladen.
Du findest zwei Download-Buttons auf der Seite. Nachdem du einen der Buttons gedrückt hast, wirst du zur offiziellen Download-Seite weitergeleitet. Hier kannst du dein Betriebssystem auswählen, in meinem Fall Windows, und die entsprechende Datei herunterladen.
Wenn du den Link in der oberen rechten Ecke namens „Models“ verwendest, erhältst du eine Liste aller verfügbaren Large und Small Language Models, die von Ollama heruntergeladen und lokal verwendet werden können.
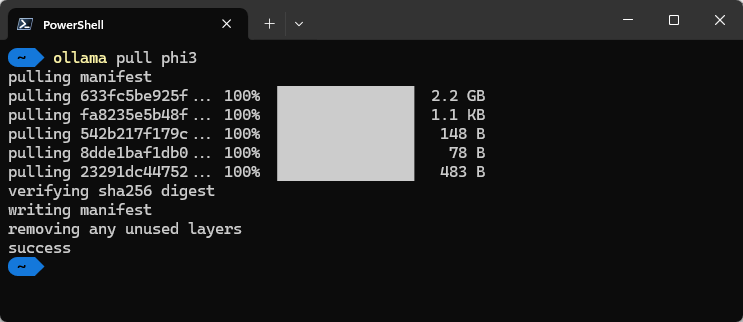
Nach der Installation kannst du ein Terminal öffnen und den Befehl ollama verwenden. Durch Eingabe von ollama pull <Modellname> kannst du das Large Language Model herunterladen. Ich möchte Phi-3, ein SLM von Microsoft, ausprobieren.
Nachdem der Download des Modells abgeschlossen ist, können wir ollama run <Modellname> verwenden, um eine Konversation mit dem entsprechenden Modell zu starten. Du musst einfach deinen Prompt eingeben und das Modell wird entsprechend antworten.
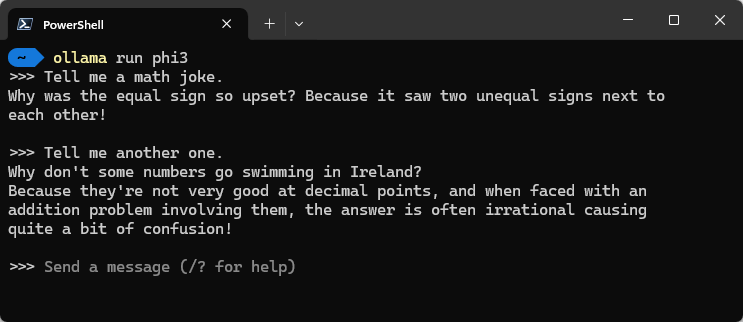
Durch Eingabe von /bye kannst du den Befehl beenden. Wenn du das Parameter --verbose zur Eingabe hinzufügst, erhältst du am Ende der Antwort einige zusätzliche Statistiken.
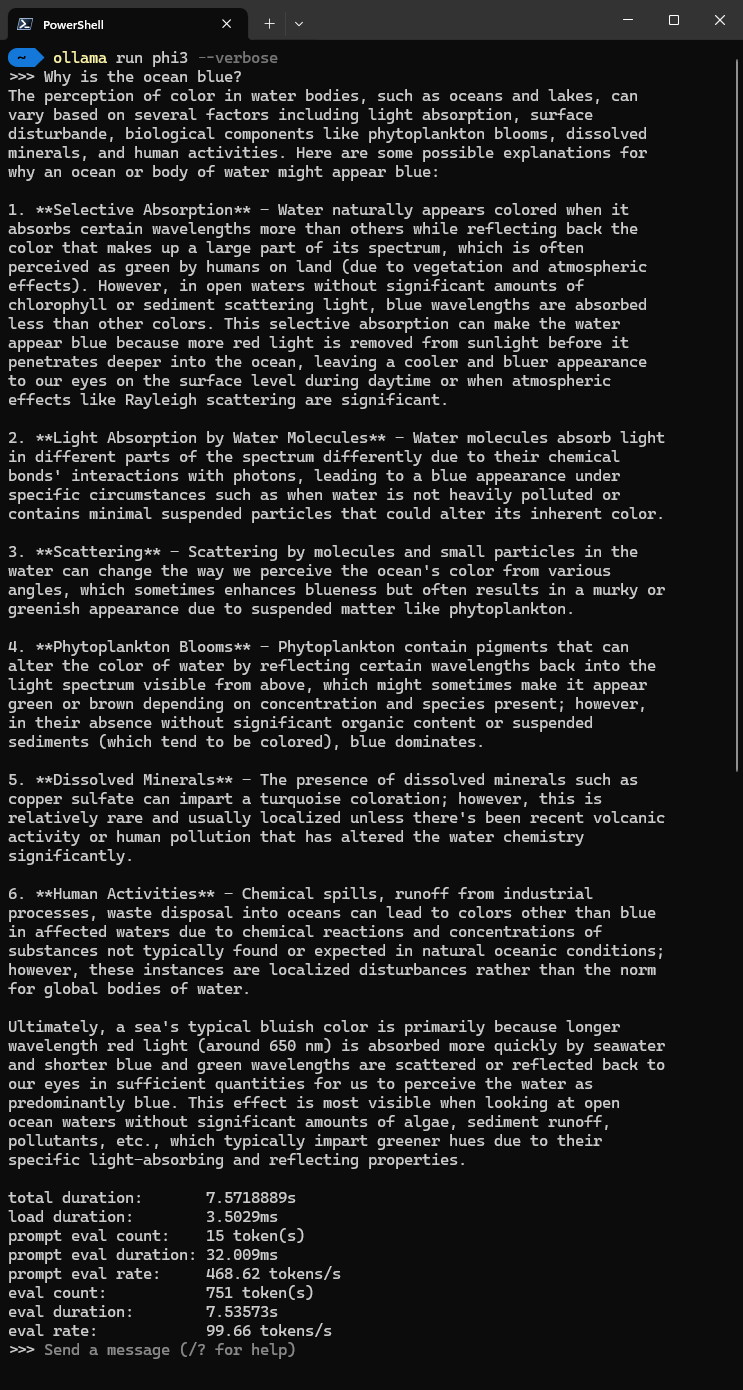
Verwendung von Ollama als Server
Ollama fungiert auch als Server, sodass wir Code schreiben können, um eine Chat-Konversation zu simulieren. Ich zeige dir zwei Möglichkeiten, wie du auf den Ollama-Server mit Python zugreifen kannst. Ich gehe davon aus, dass du Python bereits auf deinem Rechner installiert hast. Öffne Visual Studio Code und erstelle einen neuen Ordner namens ollama. Füge in diesem Ordner eine Datei namens requirements.txt hinzu, die alle benötigten Pakete enthält. In unserem Fall benötigen wir langchain_community und requests.
langchain_community==0.2.11
requests==2.32.3Jetzt erstellen wir eine weitere Datei im Ordner namens main-langchaincommunity.py. Diese Datei verwendet das Paket langchain_community, um eine Verbindung zum Ollama-Server herzustellen und einen einfachen Befehl auszuführen, der in der Konsole ausgegeben wird.
from langchain_community.llms import Ollama
# create large language model using 'phi' model
llm = Ollama(model="phi3")
# invoke the model
response = llm.invoke("Tell me a programming joke")
# print the response
print(response)Wenn du ein weiteres Terminal-Fenster öffnest, kannst du zu dem erstellten Ordner wechseln und unser Python-Skript ausführen. Du wirst einen Programmiererwitz in der Konsole sehen.

Ich zeige dir einen anderen Ansatz mit dem Paket requests. Erstellen wir eine neue Datei namens main-api.py in unserem Ordner. Auf localhost:11434 läuft der Ollama-Server und stellt den Endpunkt api/generate bereit, um eine Antwort zu generieren. Wir konfigurieren einfach die Header- und Datenobjekte und schließlich können wir unsere Methode generate_response in Python aufrufen.
import requests
import json
# define endpoint for ollama api
url = "http://localhost:11434/api/generate"
# define headers
headers = {
'Content-Type': 'application/json',
}
# define function to generate response from ollama api
def generate_response(prompt):
data = {
"model": "phi3",
"stream": False,
"prompt": prompt,
}
# make a post request to the ollama api
response = requests.post(url,
headers=headers,
data=json.dumps(data))
# check if the response is successful
if response.status_code == 200:
response_text = response.text
data = json.loads(response_text)
actual_response = data["response"]
print("Response: ", actual_response)
# if the response is not successful, print the error
else:
print("Error:", response.status_code, response.text)
generate_response("Why is the sky blue?")Wenn wir das Terminal-Fenster erneut öffnen und unser main-api.py-Skript ausführen, erhältst du ebenfalls die Antwort vom lokal laufenden Large Language Model.
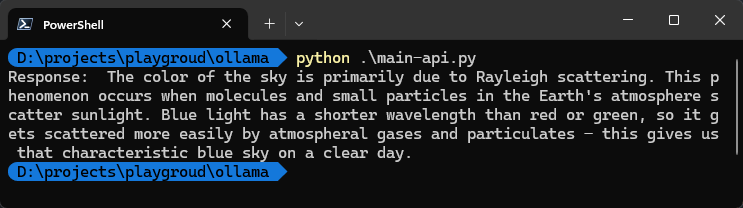
In diesem Beitrag habe ich dir erklärt, wie du Ollama auf deinem Windows-Rechner einfach installieren und Large Language Models lokal nutzen kannst.
Den verwendeten Code findest du in meinem GitHub-Repository.


GitHub Copilot Workspace: Per AI GitHub Issues bearbeiten
Artikel lesen
OenAI DevDay 2024: Die wichtigsten Neuerungen im Überblick
Artikel lesen