
In diesem Blog-Post möchte ich die Vorbereitungen klären, die notwendig sind, um das Phi-3 Mini-Modell mithilfe von ONNX als lokales Small Language Model zu nutzen. Dazu entwickeln wir eine einfache .NET-Konsolenanwendung, die zeigt, wie man das Phi-3 Mini-Modell mit ONNX integriert.
Vor nicht allzu langer Zeit hat Microsoft seine Small Language Models der Phi-Familie veröffentlicht. Während der Microsoft Build-Konferenz in Seattle wurde das neue Phi-3 Mini vorgestellt. Nun möchte ich Ihnen zeigen, wie Sie dieses Small Language Model ganz einfach in Ihrer C#-Anwendung mit der ONNX-Version verwenden können.
ONNX (Open Neural Network Exchange) ist ein Format, das KI-Modelle portabel und interoperabel über verschiedene Frameworks und Hardware hinweg macht. Es bietet ein gemeinsames Format für maschinelle Lernmodelle, erleichtert deren Austausch zwischen verschiedenen Frameworks und optimiert für verschiedene Hardwareumgebungen.
Zunächst laden wir die entsprechende ONNX-Version des Phi-3 Mini-Modells herunter. Zunächst stellen wir sicher, dass Git LFS (Large File Storage) installiert ist, indem der folgende Befehl ausgeführt wird:
git lfs installNun können wir das Modell von Hugging Face klonen.
git clone https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-onnxIm heruntergeladenen Ordner findest du ein Verzeichnis namens cpu_and_mobile/cpu-int4-rtn-block-32-acc-level-4. Dieses Verzeichnis enthält alle notwendigen Dateien. Notiere dir den Pfad zu diesem Ordner.
Öffne Visual Studio und erstelle eine neue Konsolenanwendung mit .NET 8. Installiere die beiden NuGet-Pakete Spectre.Console und Microsoft.ML.OnnxRuntimeGenAI über den NuGet-Paket-Manager.
Erstelle einen Ordner namens Utils. Erstelle in diesem Ordner eine Klasse namens ConsoleHelper. Diese Klasse dient als Wrapper für das Spectre.Console-Paket und stellt einige nützliche Methoden bereit. Die Methode ShowHeader zeigt einen stilisierten Header in der Konsole an. Die Methode GetFolderPath ruft den Pfad zu dem Ordner ab, der die ONNX-Dateien enthält. Die Methode WriteToConsole schreibt einen angegebenen Text in die Konsole.
using Spectre.Console;
namespace Phi3MiniOnnxConsole.Utils;
internal static class ConsoleHelper
{
public static void ShowHeader()
{
AnsiConsole.Clear();
Grid grid = new();
grid.AddColumn();
grid.AddRow(new FigletText("Phi-3 Mini ONNX").Centered().Color(Color.Red));
grid.AddRow(Align.Center(new Panel("[red]Sample by Thomas Sebastian Jensen ([link]https://www.tsjdev-apps.de[/])[/]")));
AnsiConsole.Write(grid);
AnsiConsole.WriteLine();
}
public static string GetFolderPath(string prompt)
{
ShowHeader();
return AnsiConsole.Prompt(
new TextPrompt<string>(prompt)
.PromptStyle("white")
.ValidationErrorMessage("[red]Invalid path[/]")
.Validate(prompt =>
{
if (!Directory.Exists(prompt))
{
return ValidationResult.Error("[red]Path does not exist[/]");
}
return ValidationResult.Success();
}));
}
public static void WriteToConsole(string text)
{
AnsiConsole.Markup($"[white]{text}[/]");
}
}Erstelle im selben Utils-Ordner eine neue Datei namens Statics.cs. Diese Datei enthält statische Eingabeaufforderungen und andere statische Inhalte.
namespace Phi3MiniOnnxConsole.Utils;
internal class Statics
{
public const string SystemPrompt
= "You are an AI assistant that helps people find information. " +
"Answer the questions briefly.";
public const string ModelLoadingMessage
= "[yellow]Loading Model...[/]";
public const string ModelInputPrompt
= "Enter the path to the [yellow]model folder[/]:";
public const string InputPrompt =
"[green]Input:[/] ";
public const string OutputPrompt =
"[green]Output:[/]";
}
Öffne die Datei Program.cs und ersetze deren Inhalt durch den folgenden Codeausschnitt. Ich werde den Code anschließend erläutern.
using Microsoft.ML.OnnxRuntimeGenAI;
using Phi3MiniOnnxConsole.Utils;
ConsoleHelper.ShowHeader();
string modelPath = ConsoleHelper.GetFolderPath(Statics.ModelInputPrompt);
ConsoleHelper.ShowHeader();
ConsoleHelper.WriteToConsole(Statics.ModelLoadingMessage);
using Model model = new(modelPath);
using Tokenizer tokenizer = new(model);
using GeneratorParams generatorParams = new(model);
generatorParams.SetSearchOption("max_length", 2048);
ConsoleHelper.ShowHeader();
while (true)
{
ConsoleHelper.WriteToConsole(Environment.NewLine);
ConsoleHelper.WriteToConsole(Statics.InputPrompt);
string? input = Console.ReadLine();
if (string.IsNullOrEmpty(input))
{
continue;
}
ConsoleHelper.WriteToConsole(Environment.NewLine);
ConsoleHelper.WriteToConsole(Statics.OutputPrompt);
string fullPrompt = $"{Statics.SystemPrompt}{input}";
using Sequences tokens = tokenizer.Encode(fullPrompt);
generatorParams.SetInputSequences(tokens);
using Generator generator = new(model, generatorParams);
while (!generator.IsDone())
{
generator.ComputeLogits();
generator.GenerateNextToken();
string output = tokenizer.Decode(generator.GetSequence(0)[^1..]);
ConsoleHelper.WriteToConsole(output);
}
ConsoleHelper.WriteToConsole(Environment.NewLine);
ConsoleHelper.WriteToConsole(Environment.NewLine);
}
Zuerst zeigen wir unseren Header an und bitten den Benutzer dann, den Pfad zum ONNX-Modellordner anzugeben.
Als Nächstes laden wir das Modell und bereiten den Tokenizer vor. Wir richten auch die GeneratorParams ein, indem wir die gewünschte Tokenlänge angeben. Je nachdem, auf welcher Maschine der Code ausgeführt wird, kann dieser Prozess einige Sekunden dauern. Daher zeigen wir eine einfache Ladeanzeige an.
Danach verwenden wir eine while-true-Schleife, um den Chat zu simulieren. Zuerst holen wir die Eingabe des Benutzers und erstellen unser Prompt, das wir zur Kommunikation mit dem Modell verwenden. Dann verwenden wir die Generator-Klasse, um die Antwort zu generieren und in die Konsole zu schreiben.
Lass uns nun die Anwendung ausführen. Zuerst musst du den Pfad zum Modellordner angeben.
Nun kannst du mit deinem lokalen Small Language Model chatten.
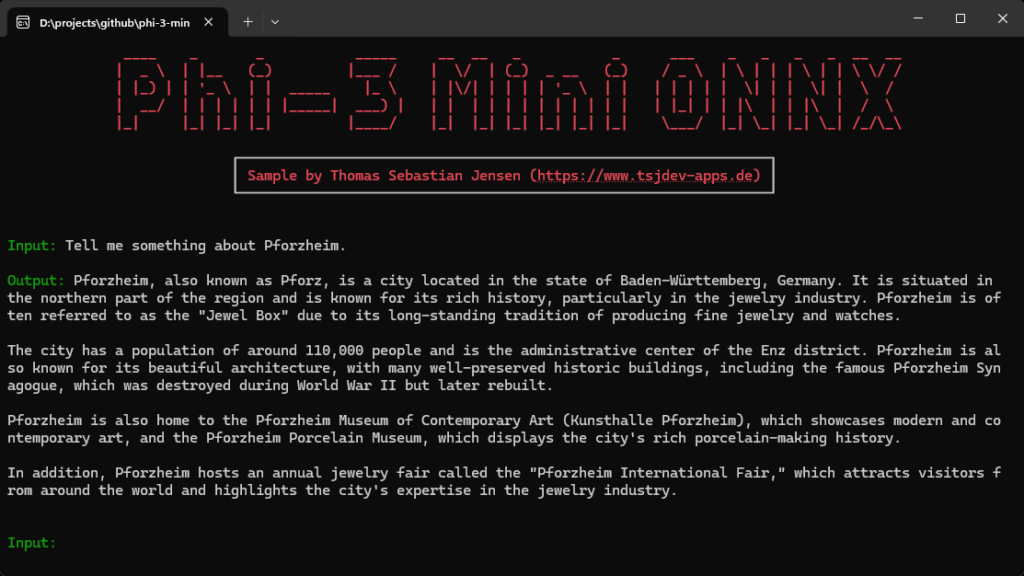
Durch Befolgen der in diesem Leitfaden beschriebenen Schritte hast du das Phi-3 Mini-Modell erfolgreich mithilfe von ONNX in eine .NET-Konsolenanwendung integriert.
Du kannst nun mit deinem lokalen Small Language Model chatten und die Möglichkeiten von ONNX für eine effiziente und portable Bereitstellung von KI-Modellen nutzen.
Für den vollständigen Quellcode und weitere Details besuche bitte mein GitHub-Repository.


GitHub Copilot: Code mit der Hilfe von AI schreiben (lassen)
Artikel lesen
Unvollständige Geschichte der KI
Artikel lesen